大家好,我是毛毛。
今天是Day 17,昨天說了今天要來看Deep Q-network,但忽然想到在看Deep Q-network前,要先來看看Markov Decision Process~
所以今天來看看Deep Q-network~ ヽ(✿゚▽゚)ノ
這篇是2018年七月刊登在Trans. Emerg. Telecommun. Technol.上的論文。
這一篇使用的方法就是基於Markov Decision Process(MDP)來實作Q2-SFC的編排問題,Q2-SFC就是關注在QoS和QoE的SFC編排演算法。
Markov Decision Process(MDP),中文稱馬可夫決策過程。
舉例來說,如下圖,在圖中有個agent機器人,它會根據它觀察環境得到的狀態去選擇它的下一步動作,然而在Deterministic Grid World中,agent會100%避開爆炸點,如圖中選擇往上走;但是在Stochastic Grid World中,agent的每個動作都是隨機性的,因此有可能往左、往上和往右走,只是可能往左的機率會低一些,但還是有可能會走到爆炸點。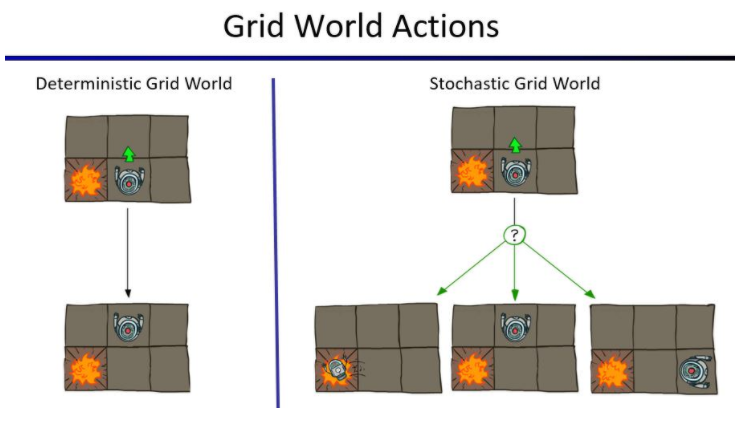
上圖來自於UC Berkeley CS188 Lecture 8
MDP含有以下內容:
State value function
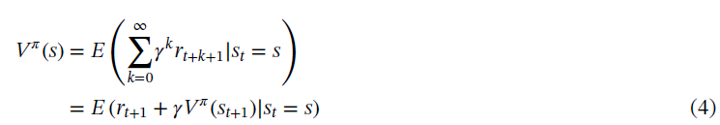
Action value function
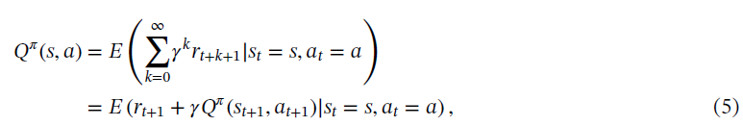
上面兩個function的推導是透過Bellman方程式,推導如下:
Future reward
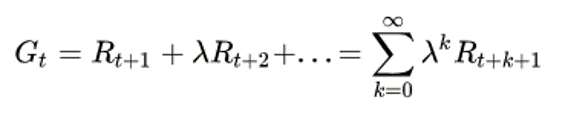
Value function
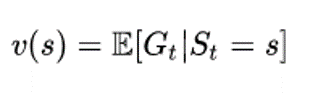
透過Bellman方程式
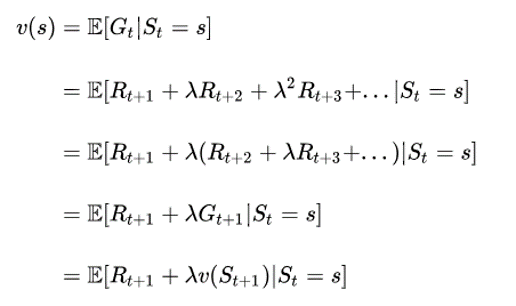
要找到MDP的最佳解決方案,就是找到使State value function最大化的策略:

根據Bellman最佳化方程式,最佳策略為:

Q2-SFC的解決方案是在policy pi下找到最佳SFC c ∗∈C

Deep Q-network的內容就放到明天啦~
大家明天見


 iThome鐵人賽
iThome鐵人賽